
Plus de connaissances

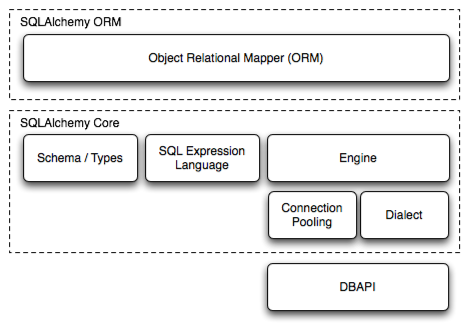
SQLAlchemy est une bibliothèque Python largement utilisée pour interagir avec des bases de données relationnelles. Elle offre une interface flexible et puissante pour travailler avec différentes bases de données, ce qui en fait un choix populaire parmi les développeurs Python. Que ce soit pour créer, interroger, mettre à jour ou supprimer des données dans une base de données, SQLAlchemy offre des outils efficaces pour gérer toutes ces tâches de manière cohérente et robuste.
L’un des principaux avantages de l’utilisation de SQLAlchemy est sa capacité à abstraire les détails spécifiques à une base de données, ce qui permet aux développeurs de travailler avec différents systèmes de gestion de bases de données (SGBD) sans avoir à modifier leur code de manière significative. Cela signifie que vous pouvez écrire votre code en utilisant les fonctionnalités et la syntaxe de SQLAlchemy, et il se chargera de traduire ces opérations en requêtes SQL compatibles avec le SGBD que vous utilisez.
Un élément clé de SQLAlchemy est son système de mappage relationnel objet-relationnel (ORM). L’ORM de SQLAlchemy permet de mapper des classes Python à des tables de bases de données et des instances d’objets à des lignes dans ces tables. Cela simplifie considérablement la manière dont les développeurs interagissent avec la base de données, car ils peuvent manipuler des objets Python familiers plutôt que d’avoir à écrire des requêtes SQL brutes.
Voici un exemple simple d’utilisation de SQLAlchemy pour interagir avec une base de données dans un interpréteur Python :
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# Création du moteur SQLAlchemy pour se connecter à la base de données
engine = create_engine('sqlite:///ma_base_de_donnees.db', echo=True)
# Définition d'une classe qui représente une table dans la base de données
Base = declarative_base()
class Utilisateur(Base):
__tablename__ = 'utilisateurs'
id = Column(Integer, primary_key=True)
nom = Column(String)
age = Column(Integer)
def __repr__(self):
return f"<Utilisateur(nom='{self.nom}', age='{self.age}')>"
# Création des tables dans la base de données
Base.metadata.create_all(engine)
# Création d'une session SQLAlchemy pour interagir avec la base de données
Session = sessionmaker(bind=engine)
session = Session()
# Exemple d'ajout d'un utilisateur à la base de données
nouvel_utilisateur = Utilisateur(nom='Jean', age=30)
session.add(nouvel_utilisateur)
session.commit()
# Exemple de récupération de tous les utilisateurs de la base de données
utilisateurs = session.query(Utilisateur).all()
for utilisateur in utilisateurs:
print(utilisateur)
Dans cet exemple, nous avons utilisé SQLAlchemy pour définir une classe Utilisateur qui est associée à une table dans la base de données. Nous avons ensuite créé une instance d’un nouvel utilisateur et l’avons ajoutée à la base de données à l’aide d’une session SQLAlchemy. Enfin, nous avons récupéré tous les utilisateurs de la base de données et les avons affichés.
Il convient de noter que SQLAlchemy prend en charge une grande variété de SGBD, y compris SQLite, PostgreSQL, MySQL, Oracle, Microsoft SQL Server, et bien d’autres encore. Cela signifie que vous pouvez utiliser la même syntaxe SQLAlchemy pour interagir avec différentes bases de données, ce qui simplifie considérablement le processus de développement et de maintenance des applications.